
Multi-View Depth Consistent Image Generation Using Generative AI Models: Application on Architectural Design of University Buildings
Published in The Association for Computer-Aided Architectural Design Research in Asia (CAADRIA 2025), Tokyo, Japan, 2025

Abstract:
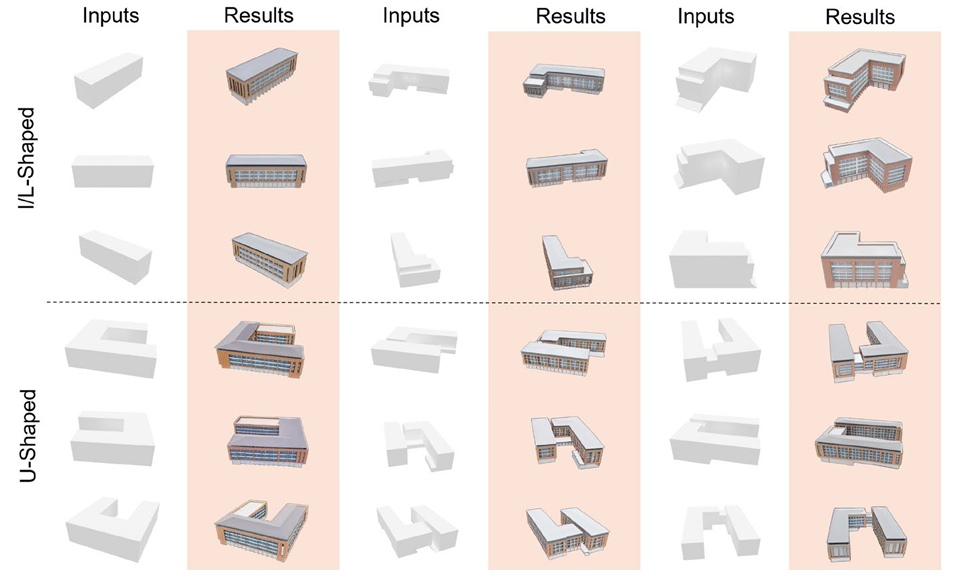
In the early stages of architectural design, shoebox models are typically used as a simplified representation of building structures but require extensive operations to transform them into detailed designs. Generative artificial intelligence (AI) provides a promising solution to automate this transformation, but ensuring multi-view consistency remains a significant challenge. To solve this issue, we propose a novel three-stage consistent image generation framework using generative AI models to generate architectural designs from shoebox model representations. The proposed method enhances state-of-the-art image generation diffusion models to generate multi-view consistent architectural images. We employ ControlNet as the backbone and optimize it to accommodate multi-view inputs of architectural shoebox models captured from predefined perspectives. To ensure stylistic and structural consistency across multi-view images, we propose an image space loss module that incorporates style loss, structural loss and angle alignment loss. We then use depth estimation method to extract depth maps from the generated multi-view images. Finally, we use the paired data of the architectural images and depth maps as inputs to improve the multi-view consistency via the depth-aware 3D attention module. Experimental results demonstrate that the proposed framework can generate multi-view architectural images with consistent style and structural coherence from shoebox model inputs.
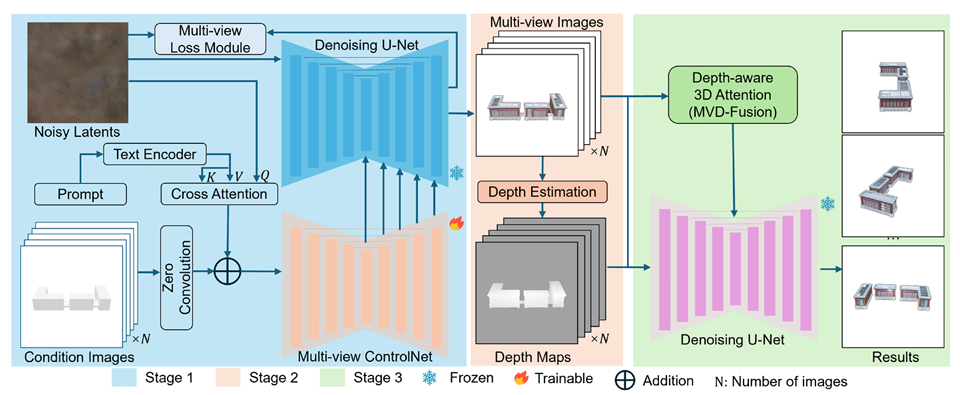
Framework:
As shown in the first stage in Figure 2, the multi-view ControlNet model is improved based on the stable diffusion model (Rombach et al., 2022), which optimizes the single-view diffusion process into a multi-view generation module. To improve the multi-view consistency, we incorporate a cross-attention mechanism. By embedding text features into noisy latent features and sharing features from different views, the generated design can more accurately follow the textual prompts (such as style description, architectural requirements, etc.), improving the generation quality and maintaining structural consistency and visual continuity across different views.

Recommended citation: **Xusheng Du**, Ruihan Gui, Zhengyang Wang, Ye Zhang, Haoran Xie.