
Sketch-Guided Scene Image Generation with Diffusion Model
Published in Computer & Graphics (Accepted), ACM/EG Expressive Symposium, 2025

Abstract:
Text-to-image models are showcasing the impressive ability to create high-quality and diverse generative images. Nevertheless, the transition from freehand sketches to complex scene images remains challenging using diffusion models. In this study, we propose a novel sketch-guided scene image generation framework, decomposing the task of scene image scene generation from sketch inputs into object-level cross-domain generation and scene-level image construction. We employ pre-trained diffusion models to convert each single object drawing into an image of the object, inferring additional details while maintaining the sparse sketch structure. In order to maintain the conceptual fidelity of the foreground during scene generation, we invert the visual features of object images into identity embeddings for scene generation. In scene-level image construction, we generate the latent representation of the scene image using the separated background prompts, and then blend the generated foreground objects according to the layout of the sketch input. To ensure the foreground objects’ details remain unchanged while naturally composing the scene image, we infer the scene image on the blended latent representation using a global prompt that includes the trained identity tokens. Through qualitative and quantitative experiments, we demonstrate the ability of the proposed approach to generate scene images from hand-drawn sketches surpasses the state-of-the-art approaches.
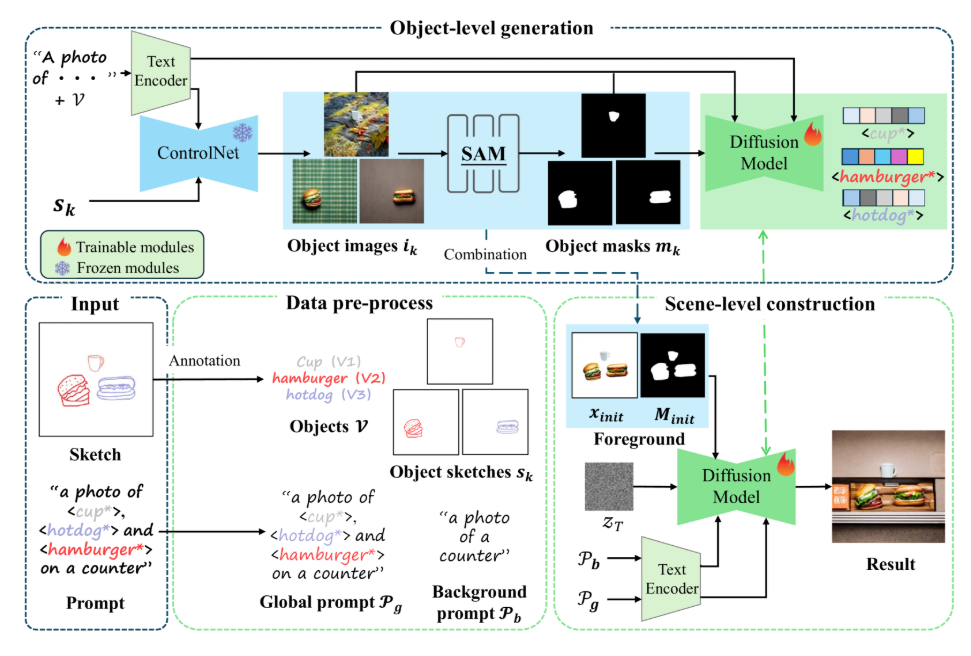
Framework:
In this work, we propose the sketch-guided scene image framework based on the text-to-image diffusion model. As shown in Figure 1, to construct images across domains while maintaining the spatial distribution of the original scene sketch, we decouple the generation of foreground and background, breaking the image generation task into two subtasks: object-level cross-domain generation and scene-level image construction. In the object-level cross-domain generation, we utilize ControlNet to generate corresponding images from independent sketch objects, effectively preserving the shape of sketches and enriching the details. To address style conflicts in objects images and maintain consistent visual features in scene generation, we customize the detailed visual features of the generated objects with special identity tokens. Specifically, we use masks for the corresponding areas to ensure the model focuses only on pixels related to the objects while ignoring background influences. In the scene-level image construction, we guide the latent representation with foregrounds by combining the foreground images and masks. We first generate the background using a background prompt, and directly blend the foreground and background in the latent space. After determining the spatial distribution, we infer the entire image with global prompts containing special identity tokens. This process bridges the separation caused by previous blending and naturally fuses the foreground and background.
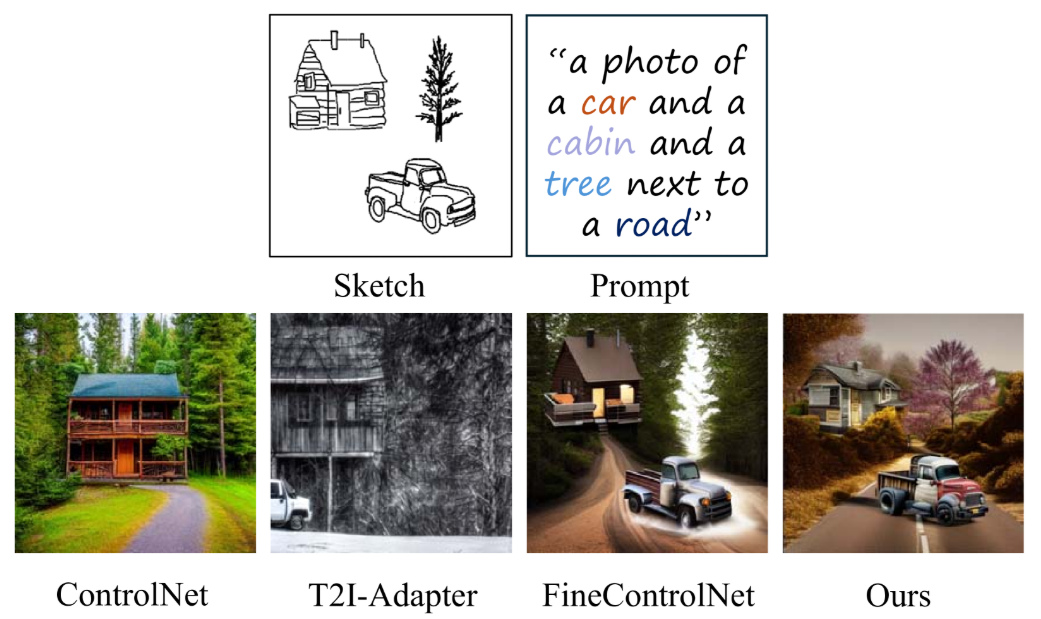
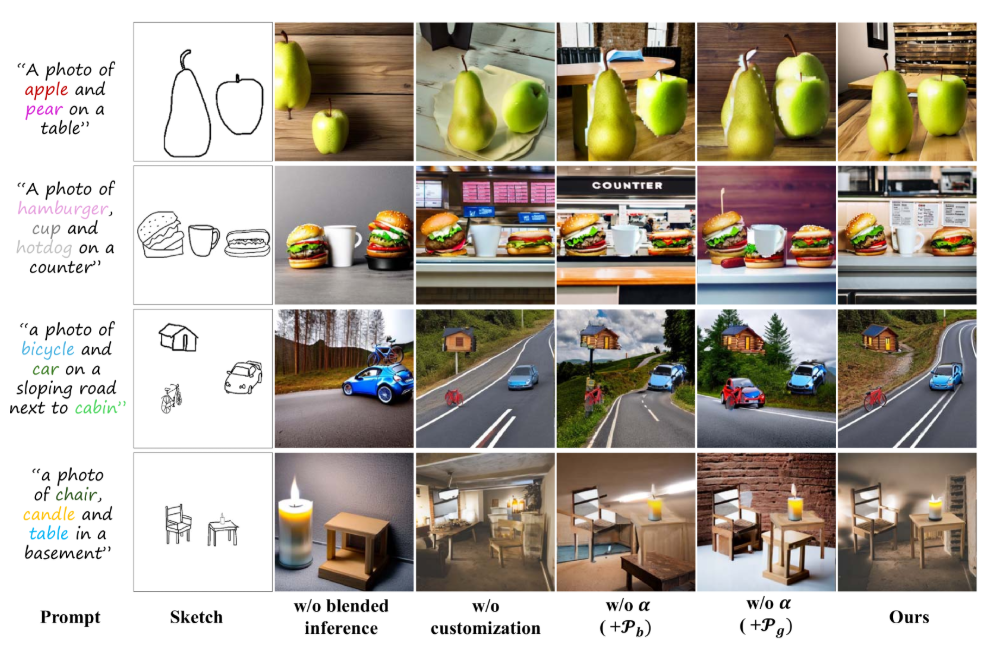
Recommended citation: Tianyu Zhang, Xiaoxuan Xie, **Xusheng Du**, Haoran Xie.