
Landscape Cinemagraph Synthesis with Sketch Guidance
Published in ACM SIGGRAPH Asia 2024, Posters, Tokyo, Japan, 2024
Introduction:
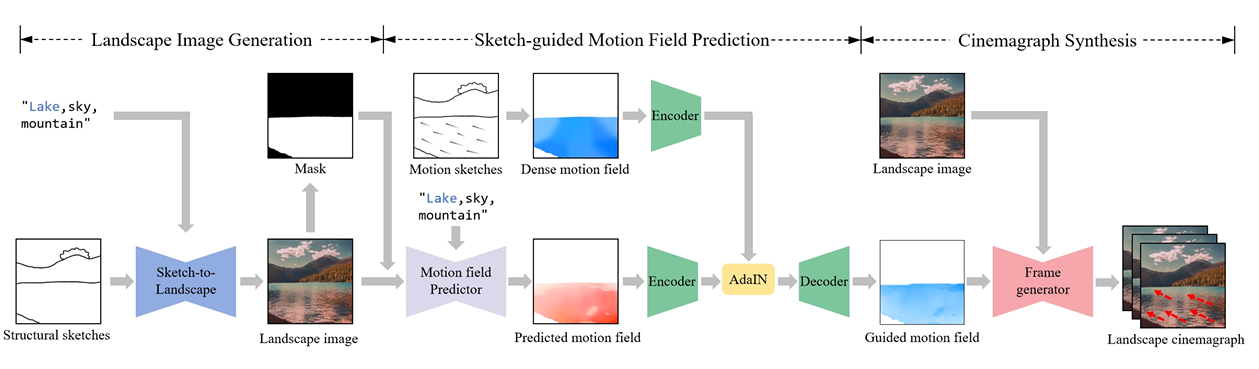
Cinemagraphs embody a captivating fusion of photography and video, animating parts of still images to create a striking visual effect. However, it is challenging to create visually pleasing cinemagraphs that require a significant investment of time and skills, especially for common users without professional knowledge and skills. In computer graphics, physics-based simulations are used to infer the motion trajectories of fluid elements which are time-consuming and domain-specific. Recently, deep learning based diffusion models can generate high-quality images and videos. Text2Cinemagraph can generate a realistic and artistic cinemagraph from a text prompt [Mahapatra et al. 2023]. The input modalities of these methods are only still real-world images or conditioning with text prompts which are difficult for common users to generate and control the landscape cinemagraph with specific design intentions. To solve these issues, we present a novel landscape cinemagraph synthesis framework with sketch-guided approach from freehand sketches using diffusion models and motion predictor as shown in Fig. 1. We propose a fine-tuned latent diffusion model to generate realistic fluid elements, such as waterfalls and sea, from the provided structural sketches and a deep-fusion method to adjust the predicted motion field based on motion sketches.
Framework:
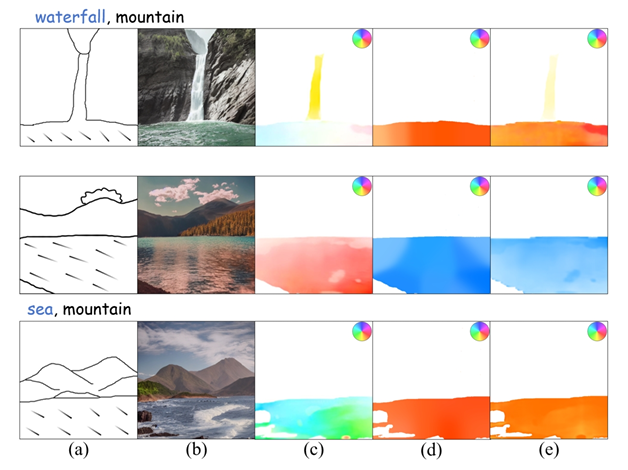
Fig. 1 illustrates the proposed framework for cinemagraph synthesis using sketch guidance. First, the landscape image generation step adopts latent diffusion model (LDM) to generate a realistic landscape image from structural sketch and text. However, the baseline LDM model has limitations in accurately generating naturalistic outdoor scenery due to an adequate quantity of high-quality landscape images in training data (Fig. 2 b). Therefore, we conduct the fine-tuning of LDM model on a real landscape dataset [Holynski et al. 2021]. Then, the pre-trained ControlNet is adopted to control the spatial regions and contents during the image generation process. To generate dynamic fluid elements while keeping background still, we extract the fluid mask from the generated image using the Grounded-SAM method Ren et al. 2024.
Recommended citation: Hao Jin, Zhengyang Wang, **Xusheng Du**, Xiaoxuan Xie, Haoran Xie.